本文最后更新于 231 天前,其中的信息可能已经有所发展或是发生改变。
1. DDL(数据定义语言)
用于创建、修改和删除数据库对象(如表、索引等)。
| 命令 |
说明 |
示例 |
SHOW DATABASES |
显示所有数据库 |
SHOW DATABASES; |
CREATE DATABASE |
创建数据库 |
CREATE DATABASE mydb; |
USE |
使用该数据库 |
USE mydb; |
SHOW TABLES |
显示当前数据库中的所有表 |
SHOW TABLES; |
CREATE TABLE |
创建表 |
CREATE TABLE users(id INT PRIMARY KEY, name VARCHAR(50)); |
ALTER TABLE |
修改表结构 |
ALTER TABLE users ADD COLUMN email VARCHAR(100); |
DROP TABLE |
删除表 |
DROP TABLE users; |
DESCRIBE或DESC |
查看表结构(字段名、类型、是否允许为空等) |
DESC users; |
TRUNCATE TABLE |
清空表数据(不可回滚) |
TRUNCATE TABLE users; |
CREATE INDEX |
创建索引 |
CREATE INDEX idx_name ON users(name); |
DROP INDEX |
删除索引 |
DROP INDEX idx_name ON users; |
CREATE VIEW |
创建视图 |
CREATE VIEW active_users AS SELECT * FROM users WHERE status = 'active'; |
DROP VIEW |
删除视图 |
DROP VIEW active_users; |
CREATE SEQUENCE |
创建序列(用于生成唯一值,如自增ID) |
CREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1; |
DROP SEQUENCE |
删除序列 |
DROP SEQUENCE seq_id; |
CREATE SCHEMA |
创建模式(命名空间) |
CREATE SCHEMA myschema; |
DROP SCHEMA |
删除模式 |
DROP SCHEMA myschema; |
2. DML(数据操作语言)
用于对数据库中的数据进行增删改查操作。
| 命令 |
说明 |
示例 |
SELECT |
查询数据 |
SELECT * FROM users; |
INSERT INTO |
插入数据 |
INSERT INTO users (id, name) VALUES (1, 'Alice'); |
UPDATE |
更新数据 |
UPDATE users SET name = 'Bob' WHERE id = 1; |
DELETE |
删除数据 |
DELETE FROM users WHERE id = 1; |
MERGE |
合并数据(插入或更新) |
MERGE INTO employees USING new_employees ON (employees.id = new_employees.id) WHEN MATCHED THEN UPDATE SET ... WHEN NOT MATCHED THEN INSERT ...; |
UPSERT |
插入或更新(部分数据库支持) |
INSERT INTO users (id, name) VALUES (1, 'Charlie') ON DUPLICATE KEY UPDATE name = 'Charlie'; (MySQL) |
CALL |
调用存储过程 |
CALL get_user_data(1); |
INSERT IGNORE |
忽略重复错误插入 |
INSERT IGNORE INTO users (id, name) VALUES (1, 'Alice'); |
REPLACE |
替换数据(若存在则删除后插入) |
REPLACE INTO users (id, name) VALUES (1, 'Alice'); |
LOAD DATA |
从文件导入数据(MySQL) |
LOAD DATA INFILE 'data.csv' INTO TABLE users FIELDS TERMINATED BY ','; |
COPY |
从文件导入数据(PostgreSQL) |
COPY users FROM '/path/to/data.csv' WITH CSV HEADER; |
COPY TO |
导出数据到文件(PostgreSQL) |
COPY users TO '/path/to/data.csv' WITH CSV HEADER; |
3. DQL(数据查询语言)
用于从数据库中检索数据。
3.1 查询语句语法
| 命令/语法 |
说明 |
示例 |
SELECT |
查询数据 |
SELECT * FROM users; |
FROM |
指定数据来源 |
SELECT name FROM users; |
WHERE |
过滤条件 |
SELECT * FROM users WHERE age > 25; |
ORDER BY |
排序结果(ASC递增,DESC递减) |
SELECT * FROM users ORDER BY name ASC; |
GROUP BY |
分组统计 |
SELECT department, COUNT(*) FROM employees GROUP BY department; |
HAVING |
对分组后的结果过滤 |
SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 5; |
DISTINCT |
去重 |
SELECT DISTINCT department FROM employees; |
LIMIT |
限制返回行数(MySQL/PostgreSQL) |
SELECT * FROM users LIMIT 10; |
TOP |
限制返回行数(SQL Server) |
SELECT TOP 10 * FROM users; |
FETCH FIRST |
限制返回行数(Oracle/PostgreSQL) |
SELECT * FROM users FETCH FIRST 10 ROWS ONLY; |
OFFSET |
跳过指定行数 |
SELECT * FROM users ORDER BY id OFFSET 10 LIMIT 10; |
JOIN |
表连接(INNER JOIN / LEFT JOIN / RIGHT JOIN) |
SELECT users.name, orders.order_id FROM users INNER JOIN orders ON users.id = orders.user_id; |
UNION |
合并两个查询结果(去重) |
SELECT name FROM users UNION SELECT name FROM admins; |
UNION ALL |
合并两个查询结果(不去重) |
SELECT name FROM users UNION ALL SELECT name FROM admins; |
INTERSECT |
取两个查询结果的交集 |
SELECT name FROM users INTERSECT SELECT name FROM admins; |
EXCEPT |
取两个查询结果的差集 |
SELECT name FROM users EXCEPT SELECT name FROM admins; |
CASE |
条件判断(类似IF-ELSE)(CASE WHEN 条件 THEN 符合条件执行的语句 ELSE 不符合条件执行的语句 END) |
SELECT COUNT(CASE WHEN age > 30 THEN 1 ELSE NULL END) AS over_30_count FROM users; |
IN |
匹配多个值 |
SELECT * FROM users WHERE id IN (1, 2, 3); |
LIKE |
模糊匹配 |
SELECT * FROM users WHERE name LIKE 'A%'; |
NOT LIKE |
不匹配 |
SELECT * FROM users WHERE name NOT LIKE 'A%'; |
BETWEEN |
在某个范围内 |
SELECT * FROM users WHERE age BETWEEN 20 AND 30; |
NOT BETWEEN |
不在某个范围内 |
SELECT * FROM users WHERE age NOT BETWEEN 20 AND 30; |
EXISTS |
判断子查询是否存在结果 |
SELECT * FROM users WHERE EXISTS (SELECT 1 FROM orders WHERE orders.user_id = users.id); |
NOT EXISTS |
判断子查询不存在结果 |
SELECT * FROM users WHERE NOT EXISTS (SELECT 1 FROM orders WHERE orders.user_id = users.id); |
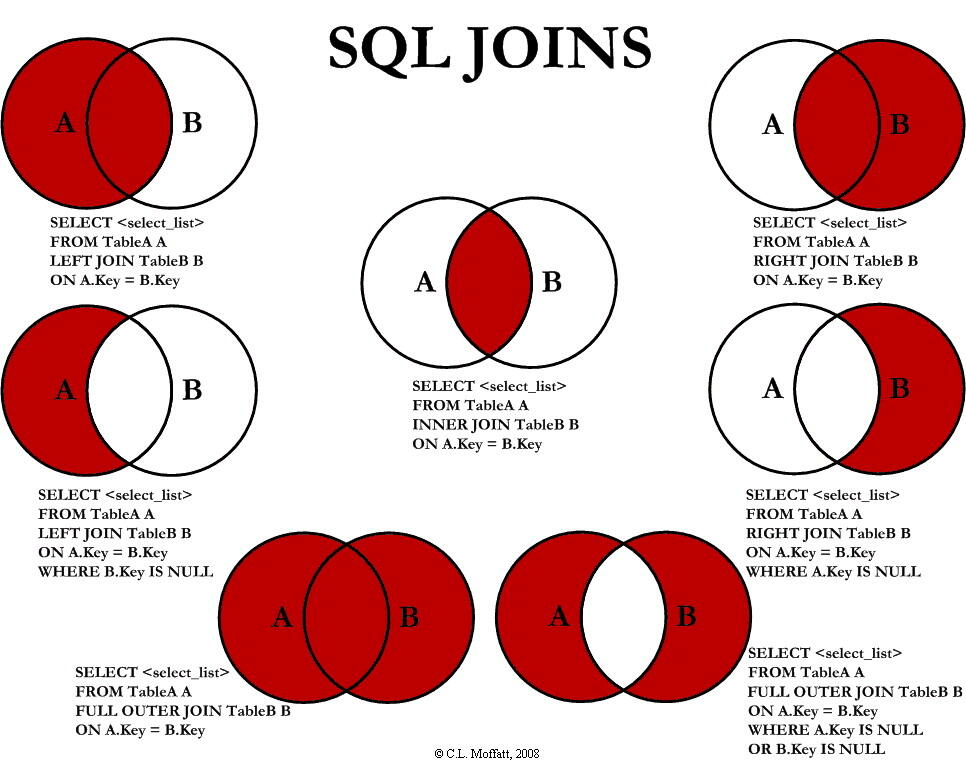
3.2 JOIN连接
| 命令/语法 |
说明 |
示例 |
INNER JOIN |
只返回两个表中匹配的行(交集) |
SELECT * FROM employees INNER JOIN departments ON employees.dept_id = departments.id; |
LEFT JOIN |
返回左表中的所有行,即使右表中没有匹配的行(右表为 NULL) |
SELECT * FROM employees LEFT JOIN departments ON employees.dept_id = departments.id; |
RIGHT JOIN |
返回右表中的所有行,即使左表中没有匹配的行(左表为 NULL) |
SELECT * FROM employees RIGHT JOIN departments ON employees.dept_id = departments.id; |
FULL OUTER JOIN |
返回左右表中所有匹配和不匹配的行(两表的并集) |
SELECT * FROM employees FULL OUTER JOIN departments ON employees.dept_id = departments.id; |
CROSS JOIN |
返回两个表的笛卡尔积(所有可能的组合) |
SELECT * FROM employees CROSS JOIN departments; |
SELF JOIN |
表与自身进行连接(常用于处理层次结构数据) |
SELECT e1.name AS employee, e2.name AS manager FROM employees e1 LEFT JOIN employees e2 ON e1.manager_id = e2.id; |
NATURAL JOIN |
自动根据相同列名进行连接(不需要指定 ON 条件) |
SELECT * FROM employees NATURAL JOIN departments; |
JOIN ... USING |
使用相同的列名进行连接,比 ON 更简洁 |
SELECT * FROM employees JOIN departments USING (dept_id); |
对于使用逗号连接,如FROM table1, table2。如果没有关联条件就是CROSS JOIN,使用WHERE增加了关联条件就是INNER JOIN。
注意,INNER JOIN是用与JOIN绑定在一起的ON来添加关联条件,而使用逗号就使用查询语句中的WHERE来添加关联条件的。
| 场景 |
默认连接类型 |
FROM table1, table2 (未指定连接条件) |
笛卡尔积(CROSS JOIN) |
FROM table1, table2 WHERE 关联条件 |
内连接(INNER JOIN) |
3.3 逻辑运算符
| 运算符 |
说明 |
示例 |
AND |
逻辑与,所有条件必须同时满足 |
SELECT * FROM users WHERE age>18 AND gender='M'; |
OR |
逻辑或,满足任意一个条件即可 |
SELECT * FROM users WHERE status='active' OR vip_level>3; |
NOT |
逻辑非,否定条件 |
SELECT * FROM users WHERE NOT deleted; |
() |
改变运算优先级 |
SELECT * FROM users WHERE (status='active' OR vip_level>3) AND age>18; |
3.4 NULL值处理
| 运算符 |
说明 |
示例 |
IS NULL |
判断是否为NULL值 |
SELECT * FROM users WHERE phone IS NULL; |
IS NOT NULL |
判断是否不为NULL值 |
SELECT * FROM users WHERE email IS NOT NULL; |
<=> |
NULL安全的等于比较 |
SELECT * FROM users WHERE name <=> NULL; |
IFNULL() |
如果为NULL则返回指定值(参数二为返回的指定值) |
SELECT IFNULL(phone,'无') FROM users; |
NULLIF() |
如果两个表达式相等则返回NULL(参数一和参数二是两个表达式) |
SELECT NULLIF('a', 'a'); |
COALESCE() |
返回第一个非NULL值 |
SELECT COALESCE(phone,email,'无') FROM users; |
ISNULL() |
判断是否为NULL(SQL Server) |
SELECT ISNULL(NULL, 'Default'); |
4. DCL(数据控制语言)
用于控制数据库的访问权限与事务处理。
| 命令 |
说明 |
示例 |
GRANT |
授予用户权限 |
GRANT SELECT, INSERT ON users TO user1; |
REVOKE |
撤销用户权限 |
REVOKE SELECT ON users FROM user1; |
COMMIT |
提交事务 |
COMMIT; |
ROLLBACK |
回滚事务 |
ROLLBACK; |
SAVEPOINT |
设置保存点(用于部分回滚) |
SAVEPOINT savepoint1; |
SET TRANSACTION |
设置事务属性(如只读、隔离级别) |
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; |
BEGIN / START TRANSACTION |
开始事务 |
START TRANSACTION; |
5. TCL(事务控制语言)
用于管理事务的提交、回滚等操作。
| 命令 |
说明 |
示例 |
BEGIN |
开始事务 |
BEGIN; |
START TRANSACTION |
开始事务(部分数据库支持) |
START TRANSACTION; |
COMMIT |
提交事务 |
COMMIT; |
ROLLBACK |
回滚事务 |
ROLLBACK; |
SAVEPOINT |
设置保存点(用于部分回滚) |
SAVEPOINT sp1; |
RELEASE SAVEPOINT |
释放保存点 |
RELEASE SAVEPOINT sp1; |
SET autocommit |
设置自动提交模式 |
SET autocommit = 0; |
6. 内置函数
6.1 聚合函数
| 函数名称 |
说明 |
示例 |
COUNT() |
计算行数 |
SELECT COUNT(*) FROM users; |
SUM() |
计算数值列总和 |
SELECT SUM(salary) FROM employees; |
AVG() |
计算平均值 |
SELECT AVG(score) FROM exams; |
MAX() |
返回最大值 |
SELECT MAX(price) FROM products; |
MIN() |
返回最小值 |
SELECT MIN(age) FROM customers; |
GROUP_CONCAT([DISTINCT] expression [ORDER BY expression [ASC|DESC]] [SEPARATOR 'separator']) |
将多行数据连接为字符串(MySQL),可选指定排序方式,可选分隔符号,默认逗号 |
SELECT GROUP_CONCAT(name) FROM departments; |
STRING_AGG() |
将多行数据连接为字符串(PostgreSQL/SQL Server) |
SELECT STRING_AGG(name, ', ') FROM teams; |
LISTAGG() |
将多行数据连接为字符串(Oracle) |
SELECT LISTAGG(name, ', ') WITHIN GROUP(ORDER BY id) FROM departments; |
VAR_POP() |
计算总体方差 |
SELECT VAR_POP(salary) FROM staff; |
STDDEV_POP() |
计算总体标准差 |
SELECT STDDEV_POP(age) FROM population; |
VAR_SAMP() |
计算样本方差 |
SELECT VAR_SAMP(score) FROM tests; |
STDDEV_SAMP() |
计算样本标准差 |
SELECT STDDEV_SAMP(price) FROM products; |
BIT_AND() |
按位与聚合 |
SELECT BIT_AND(flags) FROM permissions; |
BIT_OR() |
按位或聚合 |
SELECT BIT_OR(status) FROM devices; |
6.2 字符串函数
| 函数名称 |
说明 |
示例 |
CONCAT() |
连接多个字符串 |
SELECT CONCAT('My', 'SQL'); |
SUBSTRING() |
截取子串 |
SELECT SUBSTRING('MySQL', 2, 3); |
LOWER() / LCASE() |
转换为小写 |
SELECT LOWER('SQL'); |
UPPER() / UCASE() |
转换为大写 |
SELECT UPPER('sql'); |
TRIM() |
去除首尾空格 |
SELECT TRIM(' SQL '); |
LEFT() |
从左侧截取指定长度 |
SELECT LEFT('MySQL', 2); |
RIGHT() |
从右侧截取指定长度 |
SELECT RIGHT('MySQL', 3); |
REPLACE() |
替换字符串内容 |
SELECT REPLACE('MSSQL', 'MS', 'My'); |
REVERSE() |
反转字符串 |
SELECT REVERSE('SQL'); |
CHAR_LENGTH() |
返回字符数(多字节按1计) |
SELECT CHAR_LENGTH('中国'); |
LENGTH() |
返回字节数 |
SELECT LENGTH('中国'); |
INSTR() |
查找子串位置 |
SELECT INSTR('MySQL', 'SQL'); |
LPAD() / RPAD() |
左右填充 |
SELECT LPAD('7', 3, '0'); |
CONCAT_WS() |
用分隔符连接字符串 |
SELECT CONCAT_WS('-', '2025', '07'); |
6.3 数值函数
| 函数名称 |
说明 |
示例 |
ABS() |
绝对值 |
SELECT ABS(-10); |
CEIL() / CEILING() |
向上取整 |
SELECT CEIL(3.14); |
FLOOR() |
向下取整 |
SELECT FLOOR(3.99); |
ROUND() |
四舍五入 |
SELECT ROUND(3.1415, 2); |
TRUNCATE() |
截断数字 |
SELECT TRUNCATE(3.1415, 2); |
MOD() |
取余 |
SELECT MOD(10, 3); |
POWER() |
幂运算 |
SELECT POWER(2, 3); |
SQRT() |
平方根 |
SELECT SQRT(16); |
RAND() |
生成随机数 |
SELECT RAND(); |
SIGN() |
返回符号(-1, 0, 1) |
SELECT SIGN(-5); |
6.4 日期时间函数
| 函数名称 |
说明 |
示例 |
CURRENT_DATE |
当前日期 |
SELECT CURRENT_DATE; |
CURRENT_TIME |
当前时间 |
SELECT CURRENT_TIME; |
CURRENT_TIMESTAMP |
当前日期和时间 |
SELECT CURRENT_TIMESTAMP; |
NOW() |
当前日期和时间(MySQL) |
SELECT NOW(); |
SYSDATE() |
当前日期和时间(Oracle) |
SELECT SYSDATE FROM dual; |
GETDATE() |
当前日期和时间(SQL Server) |
SELECT GETDATE(); |
DATE_ADD() / ADD_MONTHS() |
增加日期 |
SELECT DATE_ADD('2025-01-01', INTERVAL 1 MONTH); |
DATE_SUB() / LAST_DAY() |
减少日期或获取最后一天 |
SELECT DATE_SUB('2025-01-01', INTERVAL 1 MONTH); |
DATEDIFF() |
计算两个日期之间天数差异 |
SELECT DATEDIFF('2025-01-01', '2024-12-01'); |
EXTRACT() |
提取日期部分(年、月、日等) |
SELECT EXTRACT(YEAR FROM '2025-01-01'); |
TO_DATE() |
将字符串转换为日期(Oracle) |
SELECT TO_DATE('2025-01-01', 'YYYY-MM-DD') FROM dual; |
STR_TO_DATE() |
将字符串转换为日期(MySQL) |
SELECT STR_TO_DATE('2025-01-01', '%Y-%m-%d'); |
DATE_FORMAT() |
格式化日期输出(MySQL) |
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s'); |
6.6 其他函数
| 函数名称 |
说明 |
示例 |
UUID() |
生成唯一标识符(UUID) |
SELECT UUID(); |
6.7 正则表达式
如下是MySQL调用正则表达式的方法,不同数据库有着不同的调用方法,这里略过
| 函数名称 |
说明 |
示例 |
REGEXP |
匹配正则表达式(类似 LIKE),默认不区分大小写,更建议使用REGEXP_LIKE()方法 |
SELECT * FROM users WHERE name REGEXP '^A[a-z]+'; |
REGEXP_LIKE(string, pattern[, parameter]) |
SQL中用于正则表达式匹配的函数(可选参数parameter匹配行为控制参数包括'i'不区分大小写、'c'区分大小写、'n'允许点号(.)匹配换行符 、'm':多行模式。) |
SELECT * FROM users WHERE REGEXP_LIKE(mail, '^[a-zA-Z][a-zA-Z0-9._-]*@leetcode\\.com$', 'c'); |
REGEXP_SUBSTR() |
提取匹配的子串 |
SELECT REGEXP_SUBSTR('Hello World', 'W.*') AS match; |
REGEXP_REPLACE() |
替换匹配的子串 |
SELECT REGEXP_REPLACE('Hello World', 'World', 'Universe'); |
正则表达式语法说明
表达式中一般需要对\使用转义字符\\,例如'\\s'来表示空格,'\\.'就表示点.
| 正则表达式符号 |
说明 |
示例 |
^ |
匹配字符串开头 |
^A:以字母 A 开头 |
|
匹配字符串结尾 |
e:以字母 e 结尾 |
. |
匹配任意一个字符 |
a.c:匹配 "abc"、"aac" 等 |
* |
匹配前面的字符 0 次或多次 |
a*:匹配空、"a"、"aa" 等 |
+ |
匹配前面的字符 1 次或多次 |
a+:匹配 "a"、"aa" 等 |
? |
匹配前面的字符 0 次或 1 次 |
a?:匹配 "a" 或空 |
[abc] |
匹配集合中的任意一个字符 |
[aeiou]:匹配元音字母 |
[^abc] |
匹配不在集合中的字符 |
[^aeiou]:匹配非元音字母 |
\d |
匹配数字(某些数据库支持) |
\d{3}:匹配 3 位数字 |
\w |
匹配单词字符(字母、数字、下划线) |
\w+:匹配一个或多个单词字符 |
\s |
匹配空白字符 |
\s+:匹配多个空格 |
(...) |
分组,用于捕获匹配内容 |
(ab)+:匹配 "ab"、"abab" 等 |
| |
让正则表达式匹配多种模式 |
^AA|\\sAA匹配以AA开头或AA前面有一个空格的情况 |
7. 窗口函数
| 函数名称 |
说明 |
示例 |
ROW_NUMBER() |
分配行号 |
SELECT ROW_NUMBER() OVER(PARTITION BY department ORDER BY salary DESC) AS row_num FROM employees; |
RANK() |
排名(跳过重复项) |
SELECT RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS rank FROM employees; |
DENSE_RANK() |
密集排名(不跳过重复项) |
SELECT DENSE_RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dense_rank FROM employees; |
NTILE() |
分组排序 |
SELECT NTILE(5) OVER(ORDER BY salary DESC) AS quartile FROM employees; |
LAG() |
获取前一行值 |
SELECT LAG(salary, 1) OVER(ORDER BY hire_date) AS previous_salary FROM employees; |
LEAD() |
获取后一行值 |
SELECT LEAD(salary, 1) OVER(ORDER BY hire_date) AS next_salary FROM employees; |
FIRST_VALUE() |
获取窗口中第一行的值 |
SELECT FIRST_VALUE(salary) OVER(PARTITION BY department ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS first_salary FROM employees; |
LAST_VALUE() |
获取窗口中最后一行的值 |
SELECT LAST_VALUE(salary) OVER(PARTITION BY department ORDER BY hire_date ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS last_salary FROM employees; |
8. 特殊语法与扩展
| 命令/语法 |
说明 |
示例 |
WITH |
CTE(公共表表达式) |
WITH cte AS (SELECT * FROM users WHERE age > 25) SELECT * FROM cte; |
JSON_QUERY() |
提取JSON字段(PostgreSQL) |
SELECT JSON_QUERY(data, '$.name') FROM json_table; |
JSON_EXTRACT() |
提取JSON字段(MySQL) |
SELECT JSON_EXTRACT(data, '$.name') FROM json_table; |
JSON_OBJECT() |
构建JSON对象(PostgreSQL) |
SELECT JSON_OBJECT('name' VALUE 'Alice', 'age' VALUE 25); |
JSON_ARRAY() |
构建JSON数组(PostgreSQL) |
SELECT JSON_ARRAY('Apple', 'Banana', 'Cherry'); |
XMLQUERY() |
提取XML字段(Oracle) |
SELECT XMLQUERY('/book/title' PASSING XMLTYPE(data) RETURNING CONTENT) FROM xml_table; |
XMLPARSE() |
解析XML数据(Oracle) |
SELECT XMLPARSE(CONTENT '<book><title>SQL</title></book>') FROM dual; |
9. 复杂混合示例
9.1 统计部门薪资排名及与部门平均薪资的差异
场景:分析每个部门内员工的薪资排名,并计算其薪资与部门平均薪资的差异。
WITH dept_avg_salary AS (
-- 计算每个部门的平均薪资
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT
e.employee_id,
e.first_name,
e.salary,
d.department_name,
-- 窗口函数:部门内薪资排名
RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS dept_rank,
-- 计算与部门平均薪资的差异
ROUND(e.salary - das.avg_salary, 2) AS salary_diff_from_avg,
-- 标记是否高于部门平均薪资
CASE WHEN e.salary > das.avg_salary THEN 'Above Avg' ELSE 'Below Avg' END AS salary_status
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id
JOIN
dept_avg_salary das ON e.department_id = das.department_id
ORDER BY
d.department_name, dept_rank;
关键点解析:
- CTE (
dept_avg_salary):先计算每个部门的平均薪资,避免重复聚合。
- 窗口函数 (
RANK()):按部门分组并对薪资降序排名。
- 多表连接:关联员工表、部门表和CTE结果。
- 条件逻辑 (
CASE WHEN):动态标记薪资水平状态。
9.2 递归查询组织架构层级关系
场景:查询公司中所有员工及其直接和间接下属的层级关系(递归)。
WITH RECURSIVE org_hierarchy AS (
-- 基础查询:找出所有顶级管理者(CEO或没有上级的员工)
SELECT
employee_id,
first_name,
manager_id,
1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归查询:逐级向下查找下属
SELECT
e.employee_id,
e.first_name,
e.manager_id,
oh.level + 1 AS level
FROM
employees e
JOIN
org_hierarchy oh ON e.manager_id = oh.employee_id
)
SELECT
employee_id,
first_name,
manager_id,
level,
-- 生成缩进字符串,直观显示层级
LPAD(' ', (level - 1) * 4, ' ') || first_name AS hierarchy_tree
FROM
org_hierarchy
ORDER BY
level, employee_id;
关键点解析:
- 递归CTE (
WITH RECURSIVE):
- 基础部分:定位顶级管理者。
- 递归部分:通过
JOIN逐级关联下属。
- 层级计数 (
level):跟踪每个员工的层级深度。
- 可视化缩进 (
LPAD):用空格缩进显示树形结构。
9.3 分析用户购买行为路径(漏斗分析)
场景:统计用户在电商平台中从“浏览商品”到“下单支付”的转化率。
WITH user_events AS (
-- 筛选关键事件并按时间排序
SELECT
user_id,
event_type,
event_time,
-- 窗口函数:按用户分组,按时间排序,标记事件顺序
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) AS event_seq
FROM user_activity_logs
WHERE event_type IN ('view_product', 'add_to_cart', 'checkout', 'payment_success')
),
funnel_steps AS (
-- 统计每个步骤的用户数
SELECT
event_type,
COUNT(DISTINCT user_id) AS user_count
FROM user_events
GROUP BY event_type
),
funnel_conversion AS (
-- 计算步骤间转化率
SELECT
a.event_type AS from_step,
b.event_type AS to_step,
a.user_count AS from_count,
b.user_count AS to_count,
ROUND((b.user_count * 100.0 / a.user_count), 2) AS conversion_rate
FROM funnel_steps a
JOIN funnel_steps b ON (
-- 定义漏斗步骤顺序(view_product → add_to_cart → checkout → payment_success)
(a.event_type = 'view_product' AND b.event_type = 'add_to_cart') OR
(a.event_type = 'add_to_cart' AND b.event_type = 'checkout') OR
(a.event_type = 'checkout' AND b.event_type = 'payment_success')
)
)
SELECT * FROM funnel_conversion;
关键点解析:
- 事件排序 (
ROW_NUMBER()):标记用户行为的先后顺序。
- 漏斗步骤统计:计算每个关键事件的独立用户数。
- 转化率计算:通过自连接比较相邻步骤的用户数差异。
- 动态条件连接:确保只计算相邻步骤的转化率(如“加购”到“结算”)。