1.Pandas概述
Pandas 是一个 Python 模块,是一个高性能,高效率,高水平的数据分析库,提供了强大的数据可视化分析功能。
常与NumPy和Matplotlib一起使用,用来分析.csv、.tsv、.xlsx等表格数据。
Pandas通常只是用在数据采集和存储以及数据建模和预测中间的工具,用于数据挖掘和清理。
Pandas有三种数据结构:Series、DataFrame和Panel。
- Series类似于一维数组(与Numpy 中的一维array类似,二者与Python基本的数据结构List也很相近);
- DataFrame是类似表格的二维数组,非常贴近实际数据形式,可以看作Series instances的字典形式;
- Panel(类似于三维数组)。由于Panel并不常用, 因此, 新版本的Pandas 已经将其列为过时的数据结构。
与Numpy一样,使用Pandas 需要导入pandas包,import pandas as pd
2.Series数据结构
2.1Series概述
Series类似于数组的一维数据结构,由索引(index)和值(values)关联数组组成
该数据结构类似于Excel的一列,索引(index)相当于这一列旁边的编号
2.2Series创建
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
- data是数据源 , 其类型可以是一系列的整数、字符串、浮点数等或NumPy的一维ndarray对象等。
- index是索引,列表数据类型,为数据提供标签(label),若省略则默认生成0~n-1的序号标签
- dtype是其数据类型,默认将自动判断
Series依赖于NumPy中的N维数组(ndarray)而构建, 因此, 其内部的数据要整齐划 一, 数据类型必须相同。
-
通过列表创建
data为列表结构,index可默认可指定。
index与列表元素个数一致
# 例程1 import pandas as pd a = pd.Series([10,11,12]) # 默认索引 ''' 0 10 1 11 2 12 dtype: int64 ''' b = pd.Series([20,21,22], index=['a','b','c']) # 自定义索引 ''' a 20 b 21 c 22 dtype: int64 ''' -
通过标量值创建
data为单一数据,但index一般不会省略,省略index只有一个数据对。
index在这里表达了Series类型的尺寸。
# 例程2 import pandas as pd c = pd.Series(30, index=['a', 'b', 'c']) # 指定index ''' a 30 b 30 c 30 dtype: int64 ''' -
通过字典创建
data使用字典数据类型,使用字典的“key”作索引,index可省略。
若使用index,index则在字典中进行选择操作,最终数据顺序按index顺序来。所以这里index可以不与前面元素个数保持一致,index找不到则返回值“NaN”,因为NaN是float64类型的,所以整体包括其他元素都会提升至float类型。
# 例程3 import pandas as pd d = pd.Series({'a':40,'b':41,'c':42}) ''' a 40 b 41 c 42 dtype: int64 ''' e = pd.Series({'a':40,'b':41,'c':42}, index=['c','b','d']) ''' c 42.0 b 41.0 d NaN dtype: float64 ''' -
通过ndarray创建
Series支持numpy中操作,结合numpy使用,能操作复杂数据。
data和index都可以用ndarray数组来表示,这里index同样需要与data中数据个数保持一致。
# 例程4 import pandas as pd import numpy as np f = pd.Series(np.random.randn(5), index=np.arange(5,0,-1)) ''' 5 -0.525784 4 -1.131880 3 -0.630020 2 -0.422938 1 -1.885347 dtype: float64 '''
2.3Series基本操作
Series操作类似ndarray类型,类似于Python的字典类型
2.3.1获取数据
类似于字典类型,Series中有“values”和“index”两部分,分别通过 S.values** 和 **S.index
# 续-例程3
# e = pd.Series({'a':40,'b':41,'c':42}, index=['c','b','d'])
print(e.values)
# [42. 41. nan]
print(e.index)
# Index(['c', 'b', 'd'], dtype='object')Pandas中的 object 类型比较特殊,Pandas将一些复杂的数据类型,如Python中的str、NumPy中的string、Unicode等类型都泛化成了一个对象“object”。
特别的,string类型长度不固定,所以在Pandas中,被泛化成的object对象是一个指针。
2.3.2访问数据
-
通过 in 关键字
注意对index操作,程序只会在index中搜索并相应地回”True“或”False“
类似于数据库中的in操作
-
通过 .get() 方法
对index操作,同索引访问,返回对应值,找不到则返回”None“,例:S.get(‘a’)
-
通过 索引 或 位置 访问
使用”[]“操作符,对index操作,返回对应值,找不到则报错
可以在”[]“中使用列表,访问多个数据
使用索引访问即”[]“中使用index值,使用位置访问即使用类似于列表的数字下标(0、1 … )
注意,两套索引可以并存,但不能混用,如S[[0,’b’]]就会报错
选取类型 选取方法 说明 索引名选取 data[ index ] 选取某个值 data[ indexList ] 选取多个值 基于位置选取 data[ loc ] 选取某个值 data[ locList ] 选取多个值 data[a: b, c] 选取位置a~(b-1)以及c的值 条件筛选 data[ condition] 选取满足条件表达式的值
# 续-例程3
# d = pd.Series({'a':40,'b':41,'c':42})
print('a' in d) # True
print('d' in d) # False
print(40 in d) # False
print(d.get('a')) # 40
print(d.get('d')) # None
print(d['a']) # 40
print(d[0]) # 40
print(d['d']) # 报错
print(d[ ['a','b'] ])
'''
a 40
b 41
dtype: int64
'''在对Pandas类型进行数据访问时,有时会发现数据缺失(NaN, not a number),Pandas中有 pd.isnull() 和 pd.notnull() 来检测缺失数据
pd1 = pd.Series({'a':40,'b':41,'c':42})
pd2 = pd.Series({'b':10,'c':11,'d':12})
pd3 = pd1+pd2
'''
a NaN
b 51.0
c 53.0
d NaN
dtype: float64'''
print(pd.isnull(pd3))
'''
a True
b False
c False
d True
dtype: bool'''
print(pd.notnull(pd3))
'''
a False
b True
c True
d False
dtype: bool'''切片:与NumPy相同,可以索引标签切片
注意,使用具体index索引进行切片时,包括最后一个值
s = pd.Series([1,2,3], index=['a','b','c'])
print(s[0:2])'''不包括最后一个
a 1
b 2
dtype: int64'''
print(s['a':'c'])'''包括最后一个
a 1
b 2
c 3
dtype: int64'''2.3.3向量化操作
Pandas的广播机制,类似于NumPy的广播机制,即Series变量与常量的乘法,是对Series变量中所有元素值都进行数值上的乘法运算;Series变量相加是元素间的值的相加。
Series类型在运算时,会自动对齐不同索引的数据,比如两个Series变量相加,某个索引只存在于其中一个Series变量中,则计算后不会输出值(输出NaN)
# 续-例程3
# d = pd.Series({'a':40,'b':41,'c':42})
g = pd.Series({'a':100, 'd':100})
print(d*3)'''
a 120
b 123
c 126
dtype: int64'''
print(d+d)'''
a 80
b 82
c 84
dtype: int64'''
print(d+g)'''凡是不同的索引,都不会相加,也就不会正常输出
a 140.0
b NaN
c NaN
d NaN
dtype: float64'''注:.median()方法,取Series变量的中位数。
中位数是一个可将数值集合划分为相等的上下两部分的一个数值。如果列表数据的个数是奇数,则列表中间那个数据就是列表数据的中位数;如果列表数据的个数是偶数,则列表中间那2个数据的算术平均值就是列表数据的中位数。
2.3.4其他基本操作
属性“.name”:Series对象和索引都可以有一个名字,存储在属性. name 中,名字也是Series类型的一个属性,输出时,会一并输出名字
a = pd.Series({'a':10,'b':20})
a.name = "我的Series"
a.index.name = "我的索引"
print(a)'''
我的索引
a 10
b 20
Name: 我的Series, dtype: int64'''统计方法“.decribe()”:Series中简单的统计方法
print(a.describe())'''
count 2.000000
mean 15.000000
std 7.071068
min 10.000000
25% 12.500000
50% 15.000000
75% 17.500000
max 20.000000
dtype: float64'''合并方法"S1.append(S2, ignore_index=)":
在后面追加一个Series变量,将两个Series拼接产生一个新的Series。ignore_index参数用于表示是否忽略原有index,ignore_index=True,则自动重新生成index,默认为False,即index也合并
s1 = pd.Series([1,2,3])
s2 = pd.Series([4,5,6])
s1.append(s2)注意:Series不能直接添加新数据,所以用此方法
.append()不改变两个Series,而是产生一个新的Series。
删除操作"S.drop([‘a’,’b’],axis=0,inplace=True)" :
drop可以同时对多个元素进行操作(要用[]括起来)。axis参数用于表明是对行操作还是对列操作,axis=0为行操作,axis=1为列操作。inplace参数设为True,代表原地操作,即在原数据进行操作。默认inplace参数为False,删除操作不会对原有Series变量进行,先进行了深复制。
drop选择的对象必须是index,不能用位置索引,若想用位置索引,可以先用.index()方法得到index,例S.drop(S.index([0, 1]))
3.DataFrame数据结构
3.1DataFrame概述
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame常用于表达二维数组,也可以表达多维数组
Series是带标签的一维数组,DataFrame则相当于带标签的二维数组。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引),key和value,字典的key对应DataFrame的列名称,而字典的value是一个列表,列表的长度就是行数
可以通过字典、Series等基本数据结构来构建DataFrame。 最常用的方法之一是, 先构建一个由列表或NumPy数组组成的字典, 然后再将字典作为DataFrame 中的参数
3.2DataFrame创建
DataFrame 包括值(values)、行索引(index)和列索引(columns) 3部分
创建语句:pd.DataFrame ( data,index = […],columns=[…] )
data:列表或NumPy的二维ndarray对象
index,colunms:列表,若省略则自动生成0 ~n-1的序号标签
- 从二维ndarray对象创建
- 从 一维ndarray对象 字典 创建
- 从 列表类型 字典 创建
- 从若干Series对象创建
字典的key值是DataFrame类型的列索引
DataFrame对象每一列可以是不同的数据类型
几种创建DataFrame类型变量的方式如下,其他的只要满足DataFrame变量格式的也可一试
import pandas as pd
import numpy as np
# 1.从二维ndarray数组创建
a = pd.DataFrame(np.arange(10).reshape(2,5))
print(a)'''第一行第一列为自动生成的行、列索引
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9'''
# 2.从一维ndarray对象字典创建
d = {'A':pd.Series([1,2,3], index=['a','b','c']),
'B':pd.Series([9,8,7,6], index=['a','b','c','d'])}
a = pd.DataFrame(d)
print(a)'''注意DataFrame对象可以自动对齐,因为每一列数据类型可以不一样,所以NaN只影响所在那一列
A B
a 1.0 9
b 2.0 8
c 3.0 7
d NaN 6'''
# 3.从列表类型字典创建
d = {"第一列":[1,2,3], "第二列":[4,5,6]}
a = pd.DataFrame(d, index=['第一行','第二行','第三行'])
print(a)'''data的索引为DataFrame类型的列索引
第一列 第二列
第一行 1 4
第二行 2 5
第三行 3 6'''
# 4.从若干Series对象创建
row1 = pd.Series(np.arange(3),index=['one','two','three'])
row2 = pd.Series(np.arange(3),index=['a','b','c'])
row1.name='Series1'
row2.name='Series2'
df = pd.DataFrame([row1,row2])
print(df)'''Series名字成为了DataFrame类型的行索引
one two three a b c
Series1 0.0 1.0 2.0 NaN NaN NaN
Series2 NaN NaN NaN 0.0 1.0 2.0'''3.3DataFrame操作
3.3.1数据访问
通过调用DataFrame属性来获取DataFrame变量的属性值
DataFrame一些基本属性如下
| 函数 | 返回值 |
|---|---|
| DF.values | 元素 |
| index | 索引 |
| columns | 列名 |
| dtypes | 类型 |
| size | 元素个数 |
| ndim | 维度数 |
| shape | 数据形状(行列数目) |
| axes | 行标签,列标签 |
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(10).reshape(2,5))
print(a.columns)'''
RangeIndex(start=0, stop=5, step=1)'''
print(a.columns.values)'''
[0 1 2 3 4]'''常用方法,用于查看DataFrame指定条件数值:
| 名称 | 描述 |
|---|---|
| DF.describe() | 产看数据按列的统计信息 |
| describe().T | 产看数据按列的统计信息并转置 |
| info() | 打印DataFrame对象信息 |
| head(n) | 返回前n行,默认5行 |
| tail(n) | 返回后n行,默认5行 |
| value_counts() | 查看某列有多少不同值 |
| sample(n) | 随机抽取n个样本 |
| dronpna() | 将数据集合中所有缺失值删除 |
| groupby() | 按指定条件分组 |
像Series类型一样,也可以使用位置或序号进行访问,DataFrame的相关选取方法如下,操作类似于Series,这里不再列举点此跳转Series访问数据
注:现在DataFrame取消了.ix()方法,需要分别使用 .loc()方法(索引名选取) 和 .iloc()方法(位置选取)。
单纯的df[]不支持同时对行和列选取(即不支持df[index, col]),同时选取某行某列需要使用.loc()或.iloc()。
df[]这样默认是对列进行选取,要是对行,则要用到.loc()或.iloc()
| 选取类型 | 选取方法 | 说明 |
|---|---|---|
| 索引名选取 | df[ col ] | 选取某列 |
| df[ colList ] | 选取某几列 | |
| df.loc[ index, col] | 选取某行某列 | |
| df.loc[ indexList, colList ] | 选取多行多列 | |
| 基于位置选取 | df.iloc[ iloc, cloc ] | 选取某行某列 |
| df.iloc[ ilocList, clocList ] | 选取多行多列 | |
| df.iloc[ a:b, c:d ] | 选取位置a~(b-1)行,c~(d-1)列 | |
| 条件筛选 | df.loc[ condition, colList ] | 使用索引构造条件表达式 选取满足条件表达式的行 |
| df.iloc[ condition, clocList ] | 使用位置序号构造条件表达式 选取满足条件的行 |
注:DataFrame类型支持用成员访问符 . 进行访问,如访问df1变量的‘one’列df1.one
3.3.2布尔索引
Dataframe布尔索引较为繁琐
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data[data<5] # 则对所有值进行逻辑比较,输出满足条件的,使不满足条件的为NaN
'''
one two three four
Ohio 0.0 1.0 2.0 3.0
Colorado 4.0 NaN NaN NaN
Utah NaN NaN NaN NaN
New York NaN NaN NaN NaN'''
data[data['three']>5] # 则输出'three'列大于5的行
'''
one two three four
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15'''
data.iloc[:, :3][data.three > 5] # 追加布尔索引,追加判断
'''
one two three
Colorado 0 5 6
Utah 8 9 10
New York 12 13 14'''DataFrame同Series一样进行向量化操作,有着差不多的广播机制,这里不再赘述
3.3.3切片
df.loc[2:4, ['a', 'b]] 与 df[2:5][['a','b']]
前一种可以取到4,后一种不能取到5。对.loc()用切片,是对其索引值进行切片,同Series,是可以取到末尾索引值的,后一种就是一般的切片了(根据位置索引)。
df.iloc[1:2]
3.3.4删除操作
.drop(data, axis= , inplace= )方法,data可以是列名或行名,可以是整个DataFrame变量,0也可以具体指定。axis参数必须要加上。inplace可以不写,则默认为False,即返回的是原DataFrame变量的复制,不会对原有数据进行删除,使用“inplace=True”时实现真正意义上的删除
DataFrame是一种表格型数据结构,既有行索引 、也有列索引。DataFrame中引入了“轴(axis)“的概念,以便区分这两个索引,并且更方便地操作数据。
axis =1与axis = ‘columns’是等价的,列索引。
axis = 0与axis = ‘index’是等价的,行索引。
d = {"第一列":[1,2,3], "第二列":[4,5,6]}
a = pd.DataFrame(d, index=['第一行','第二行','第三行'])
print(a)'''
第一列 第二列
第一行 1 4
第二行 2 5
第三行 3 6'''
a.drop('第一列', axis=0, inplace=True) # 报错,与axis不对应
a.drop('第一列', axis=1, inplace=True)
print(a)'''
第二列
第一行 4
第二行 5
第三行 6'''3.3.5添加操作
-
添加行
使用 .loc()方法 利用索引名或位置索引添加
可以使用另一个DataFrame变量,一次性添加多个,即使用.append()方法,将另一个DataFrame变量追加到目标DataFracme变量后 。
注:使用ignore_index=Ture参数可以忽略之前索引,重新自动列索引,默认也会使索引也追加,即默认ignore_index=False。
a = pd.DataFrame([1], index=['第一行'], columns=['第一列']) print(a)''' 第一列 第一行 1''' a.loc[2] = [2] a.loc['第三行'] = [3] print(a)''' 第一列 第一行 1 2 2 第三行 3''' a = pd.DataFrame([1], index=['第一行'], columns=['第一列']) b = pd.DataFrame([2, 3], index=['第二行', '第三行'], columns=['第一列']) print(a.append(b))''' 第一列 第一行 1 第二行 2 第三行 3''' -
添加列
因为DataFrame数据类型默认是对列操作,所以添加列可以直接在DataFrame变量后使用 [] 添加。当然也可以使用pd.concat([df1,df2],axis=1)函数将两个或多个DataFrame变量结合,必须要使用axis参数,且一般令axis=1。若令axis=0可能会得不到想要的结果
a = pd.DataFrame([1], index=['第一行'], columns=['第一列']) print(a)''' 第一列 第一行 1''' a[2] = [2] a['第三列'] = [3] print(a)''' 第一列 2 第三列 第一行 1 2 3''' a = pd.DataFrame([1], index=['第一行'], columns=['第一列']) b = pd.DataFrame({'第二列': 2, '第三列': 3}, index=['第一行']) print(pd.concat([a, b], axis=1))'''令axis=1 第一列 第二列 第三列 第一行 1 2 3''' print(pd.concat([a, b], axis=0))'''令axis=0 第一列 第二列 第三列 第一行 1 NaN NaN 第一行 NaN 2 3'''
注意:用“df[]=值”这种方法,若数值数目不等于行数目:
若数值数目等于1(行数目>值数目=1),则会触发广播机制,每一行都为这个值;若数值数目介于行数目与1之间(行数目>值数目>1),则因无法赋值且不能触发广播机制而报错。
同样适用于下面修改操作
-
实现Join操作
使用
pd.merge(DF1, DF2, on='key')left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})''' key lval 0 foo 1 1 foo 2''' right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})''' key rval 0 foo 4 1 foo 5''' pd.merge(left, right, on='key')''' key lval rval 0 foo 1 4 1 foo 1 5 2 foo 2 4 3 foo 2 5'''
3.3.6修改操作
修改数据时直接对选择的数据赋值即可。
需要注意的是,数据修改是直接对DataFrame数据修改,操作无法撤销,因此更改数据时要做好数据备份。
方法 .reindex() 可以根据新索引进行重排,如果某个索引值当前不存在,就引入缺失值
obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
'''
d 4.5
b 7.2
a -5.3
c 3.6
dtype: float64'''
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
'''
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64'''3.4排序
根据条件对数据集排序(sorting)也是一种重要的内置运算。要对行或列索引进行排序(按字典顺序),可使用sort_index等方法,它将返回一个已排序的新对象。对于DataFrame,则可以根据任意一个轴上的索引进行排序。
.sort_index(axis=0, ascending=True) :
axis参数用于DataFrame对象指定行、列,ascending参数指定排序方式(True为升序,False为降序,默认为True)
.sort_values(by=) :
按值进行排序,任何缺失值都会被放在末尾,当排序一个DataFrame时,若希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的by(对一个列就by=”,对多个列就使用[]传入名称列表,by=[ ])选项即可达到该目的
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),
index=['three', 'one'],
columns=['d', 'a', 'b', 'c'])
frame.sort_index(axis=1)
'''
a b c d
three 1 2 3 0
one 5 6 7 4'''
obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])
obj.sort_values()
'''
4 -3.0
5 2.0
0 4.0
2 7.0
1 NaN
3 NaN
dtype: float64'''
frame = pd.DataFrame({'b': [4, 7, -3, 2], 'a': [0, 1, 0, 1]})
frame.sort_values(by=['a', 'b'], ascending=[True,True])
'''
b a
2 -3 0
0 4 0
3 2 1
1 7 1'''4.Pandas聚合和分组运算
聚合(Aggregation)和分组其实是紧密相连的。 Pandas中 , 聚合更侧重于描述将多个数据按照某种规则(即特定函数)聚合在一起, 变成一个标量(即单个数值)的数据转换过程。
聚合的流程大致是这样的:先根据一个或多个 “键”(通常对应列索引)拆分Pandas对象(Series 或DataFrame等) ;然后根据分组信息对每个数据块应用某个函数 , 这些函数多为统计意义上的函数, 包括但不限于最小值(min)、最大值(max)、平均值(mean)、中位数(median)、众数(mode),计数 (count) 、去重计数 (nunique)、 求和(sum)、标准差(std)、var(方差)、偏度(skew)、 峰度(kurt)及用户自定义函数。
4.1聚合运算
Pandas聚合运算同NumPy聚合运算
聚合操作有:
| 方法名称 | 说明 | 方法名称 | 说明 |
|---|---|---|---|
| count | 计算分组的数目,包括缺失值。 | cumcount | 对每个分组中组员的进行标记,0至n-1。 |
| head | 返回每组的前n个值。 | size | 返回每组的大小。 |
| max | 返回每组最大值。 | min | 返回每组最小值。 |
| mean | 返回每组的均值。 | std | 返回每组的标准差。 |
| median | 返回每组的中位数。 | sum | 返回每组的和。 |
.agg()
用于将多种规则放在一起以列表形式输出,常用于与聚合分组运算一起使用
agg方法也支持axis参数的使用
import pandas as pd
data = pd.Series([4.5, 7.2, -5.3, 3.6])
print(data.agg(['min', 'max', 'mean']))
'''
min -5.3
max 7.2
mean 2.5
dtype: float64
'''.mode
.value_counts()
返回的是一个Series对象,前面是值,后面是这个值的个数
有参数normalize=,当normalize=True时,得到不同值的占比率
有参数ascending=,当ascending=True时,令其升序,不会默认的
data.Sex.value_counts()
'''
M 4
F 2
Name:Sex,dtype:int64'''4.2偏度(Skewness) 和 峰度(Kurtosis)
偏度与峰度是特别的特征值,分别调用skew 、 kurt
偏度,描述分布“偏离对称性程度”的特征数,如图,表明了图像相对于对称而言是左偏还是右偏
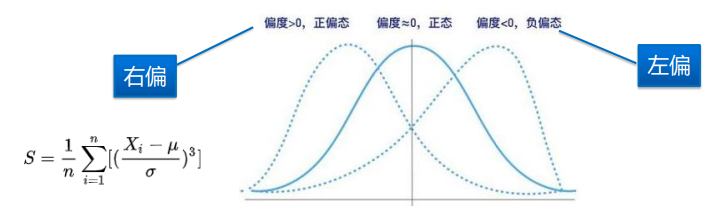

峰度,描述分布是平坦还是陡峭的统计量,以正态分布为标杆,低于正态分布,峰度值为负;高于为正
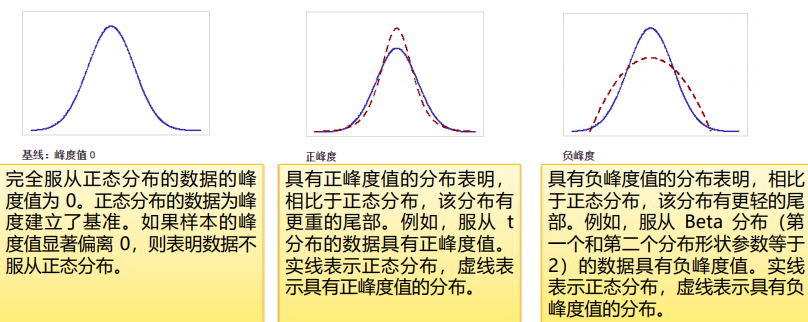
调用偏度和峰度如下:
import pandas as pd
data = pd.Series([4.5, 7.2, -5.3, 3.6])
print(data.skew()) # -1.5129229071634143
print(data.kurt()) # 2.7458056470900054
print(data.agg(['skew','kurt']))4.3groupby() 分组运算
.groupby()方法用于分组
例如:按’rank’分组
ldf.group(‘rank’)
groupby()可以结合聚合操作,作用于DataFrame这样的多维数组
例1:按’rank’分组后的数据的salary这一列实施求均值操作
ldf. groupby(‘rank’)[[‘salary’]].mean ()
例2:ldf1.groupby(‘分公司’)[‘薪水’].max()
说明:.groupby(‘分公司’)是按’分公司’分组,[‘薪水’]是取前面得到的多维数组的’薪水’这一列,.max()是取这一列的最大值
使用groupby()后得到的同普通pandas对象,后面用[]即相当于普通pandas对象一样了,使用[]访问其中数据,再在后面使用聚合方法进行聚合操作
注:用双层方括号将特定的列(通常用于多个列)括起来 ,则返回的结果是一个DataFrame对象。用单层方括号将指定列括起来, 这时输出的结果是一个Series对象
分组和聚合通常会结合在一起使用。比如:通过rank分组之后 , 我们想求得salary 和service这两列的均值 、 标准差和偏度 ,
df. groupby (‘rank’) [ [‘salary’,’service’ ]]. agg ([‘mean’,’std’,’skew’])
5.Pandas文件操作
5.1概述
到此,涉及Pandas的统计分析基础
统计分析是数据分析的重要组成部分,几乎贯穿整个数据分析的流程,运用统计方法,将定量与定性结合,进行的研究活动即为“统计分析”。统计分析除了包含单一数值型特征的数据集中趋势、离散趋势和峰度与偏度等统计知识外,还包含多个特征比较计算等知识。
数据读写:数据读取是进行预处理、建模与分析的前提。不同数据源需要不同的函数,pandas内置了10多个数据读/写函数,常见的数据源有3种:数据库、文本文件(一般文本文件和CSV)、Excel文件,占据80%以上的数据读取任务。
5.2对文本文件操作
5.2.1文本文件读取
文本文件,指一般文本文件和CSV文件
使用pd.read_table()函数来读取文本文件。
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
使用pd.read_csv()函数来读取csv文件。
pandas.read_csv(filepath_or_buffer, sep=’,’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
这两函数的参数说明如下:
| 参数名称 | 说明 |
|---|---|
| filepath | 接收string。代表文件路径。无默认。 |
| sep | 接收string。代表分隔符。read_csv默认为“,”,read_table默认为制表符“[Tab]”。 |
| header | 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。 |
| names | 接收array。表示列名。默认为None。 |
| index_col | 接收int、sequence或False。表示索引列的位置,取值为sequence则代表多重索引。默认为None。 |
| dtype | 接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None。 |
| engine | 接收c或者python。代表数据解析引擎。默认为c。 |
| nrows | 接收int。表示读取前n行。默认为None。 |
注意:
- read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
- header参数是用来指定列名的,如果是None则会添加一个默认的列名。
order = pd.read_csv(‘J:/数据可视化课程/data/工作量.csv’,encoding = ‘gbk’,header=0) - encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误。
例程:
## 使用read_table读取订单信息表
order = pd.read_table('../data/meal_order_info.csv',sep = ',',encoding = 'gbk')
print('使用read_table读取的订单信息表的长度为:',order)
## 使用read_csv读取订单信息表
order1 = pd.read_csv('../data/meal_order_info.csv',encoding = 'gbk')
print('使用read_csv读取的订单信息表的长度为:',order1)
(GBK主要用于中文编码,包含全部中文字符,长度2字节;utf-8包含全世界所有字符,长度1-6字节)
order2 = pd.read_csv(‘Salaries.csv',encoding = 'gbk')5.2.2文本文件存储
文本文件的存储和读取类似,结构化数据可以通过pandas中的.to_csv函数 实现 将DataFrame对象(可以是其他文件格式)以csv文件格式存储文件。
.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None)
参数说明如下:
| 参数名称 | 说明 |
|---|---|
| path_or_buf | 接收string。代表文件路径。无默认。 |
| sep | 接收string。代表分隔符。默认为“,”。 |
| na_rep | 接收string。代表缺失值。默认为“”。 |
| columns | 接收list。代表写出的列名。默认为None。 |
| header | 接收boolean,代表是否将列名写出。默认为True。 |
| index | 接收boolean,代表是否将行名(索引)写出。默认为True。 |
| index_labels | 接收sequence。表示索引名。默认为None。 |
| mode | 接收特定string。代表数据写入模式。默认为w。 |
| encoding | 接收特定string。代表存储文件的编码格式。默认为None。 |
例程:
import pandas as pd
order = pd.read_table('D:/testPy/工作量.csv',sep = ',',encoding = 'gbk')
## 将order以csv格式存储
order.to_csv('D:/testPy/工作量1.csv',sep = ',',index = False,encoding='gbk')
#order.to_csv(‘D:/testPy/工作量1.csv’,sep = ‘;’,index = False,encoding=‘gbk’) 分隔符为;
#order.to_csv(‘D:/testPy/工作量1.csv’,sep = ‘,’,index = False,)无存储编码5.3对Excel文件操作
5.3.1Excel文件读取
使用pd.read_excel()函数来读取“xls”、“xlsx”两种Excel文件。
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
参数说明如下:
| 参数名称 | 说明 |
|---|---|
| io | 接收string。表示文件路径。无默认。 |
| sheetname | 接收string、int。代表excel表内数据的分表位置。默认为0。 |
| header | 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。 |
| names | 接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None。 |
| index_col | 接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None。 |
| dtype | 接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None。 |
注意,出现Excel文件读取出错时:
原因可能是xlrd更新到了高版本,只支持.xls文件。所以pandas.read_excel(‘xxx.xlsx’)会报错。
-
可以安装旧版xlrd,在cmd中运行:
pip uninstall xlrd
pip install xlrd==1.2.0
-
可以用openpyxl代替xlrd打开.xlsx文件:
df=pandas.read_excel(‘data.xlsx’,engine=‘openpyxl’) -
将xlsx另存为老版本xls
5.3.2Excel文件储存
将DataFrame对象文件存储为Excel文件,可以使用.to_excel()方法。
.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
与to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1。
6.数据清洗
用于对采集的数据进行重新审查和校验
删除重复信息、纠正存在的错误、保证数据一致性
6.1检测缺失值
data.isnull()
data.notnull()
对DataFrame类型使用data.isnull()结果如下:
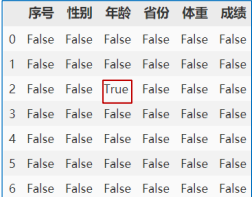
在NumPy中有着 data.isnan()** 这样的检测缺失值的函数,在Pandas中是 **data.isna()
6.2删除缺失值
data.dropna(axis=, how=, thresh=, subset=, inplace=)
axis:默认=0,删除缺失值所在的一整行;axis=1,删除列
how:默认=’any’,只要有缺失值就删除;=’all’,必须全是缺失值才会删除
thresh:只留下有效数据大于等于thresh值(个数>=n)的行或列
subset:对指定列进行缺失值删除处理
inplace:=True,更改原数据
6.3填充缺失值
data.fillna(value, method=, inplace=, ...)
value:填充值,可以是标量、字典或Series、DataFrame
method:=’ffill’,用前一列数据填充;=’bfill’,用后一列数据填充
inplace:略
注意:参数value并不是必须的,.fillna()有两种填充方式,即用value或用method,例:data.fillna(20)、data.fillna(method=’bfill’)
6.4数据去重
数据重复如下:
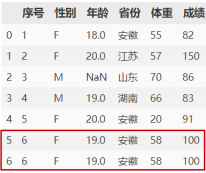
data.drop_duplicates(subset=None, keep='first', inplace=)
subset:可以是列表,用于指定特定列,默认所有列
keep:默认=’first’,删除重复项,并保留第一次出现的项;=’last’,删除重复项,并保留最后一次出现的项;=’False’:删除所有重复项,不保留
7.数据透视表
透视表(pivot table)是一种常见的数据汇总工具,能根据一个或多个键对数据进行聚合,并根据行列分组键将数据分配到不同矩形区域。
这里略将,详细的请参考其他资料
需要多个groupby时,用这个代替
pd.pivot_table(data, index=, values=, aggfunc=)
data:要处理的对象
index:透视表的索引,用于index的列会成为透视表的索引,若对index=列表,即让多列用于索引,则前面的一列会按相同值进行聚合
values:要查看的值
aggfunc:表明处理相同索引的值,使用聚合函数,默认求平均值,也可以手动使用其他聚合函数
例:pd.pivot_table(df, index=[‘a’,’b’], values=[‘c’,’d’], aggfunc={‘c’:np.sum, ‘d’:len})